

Landslide Susceptibility Mapping in a Mountainous Area Using Machine Learning Algorithms


 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
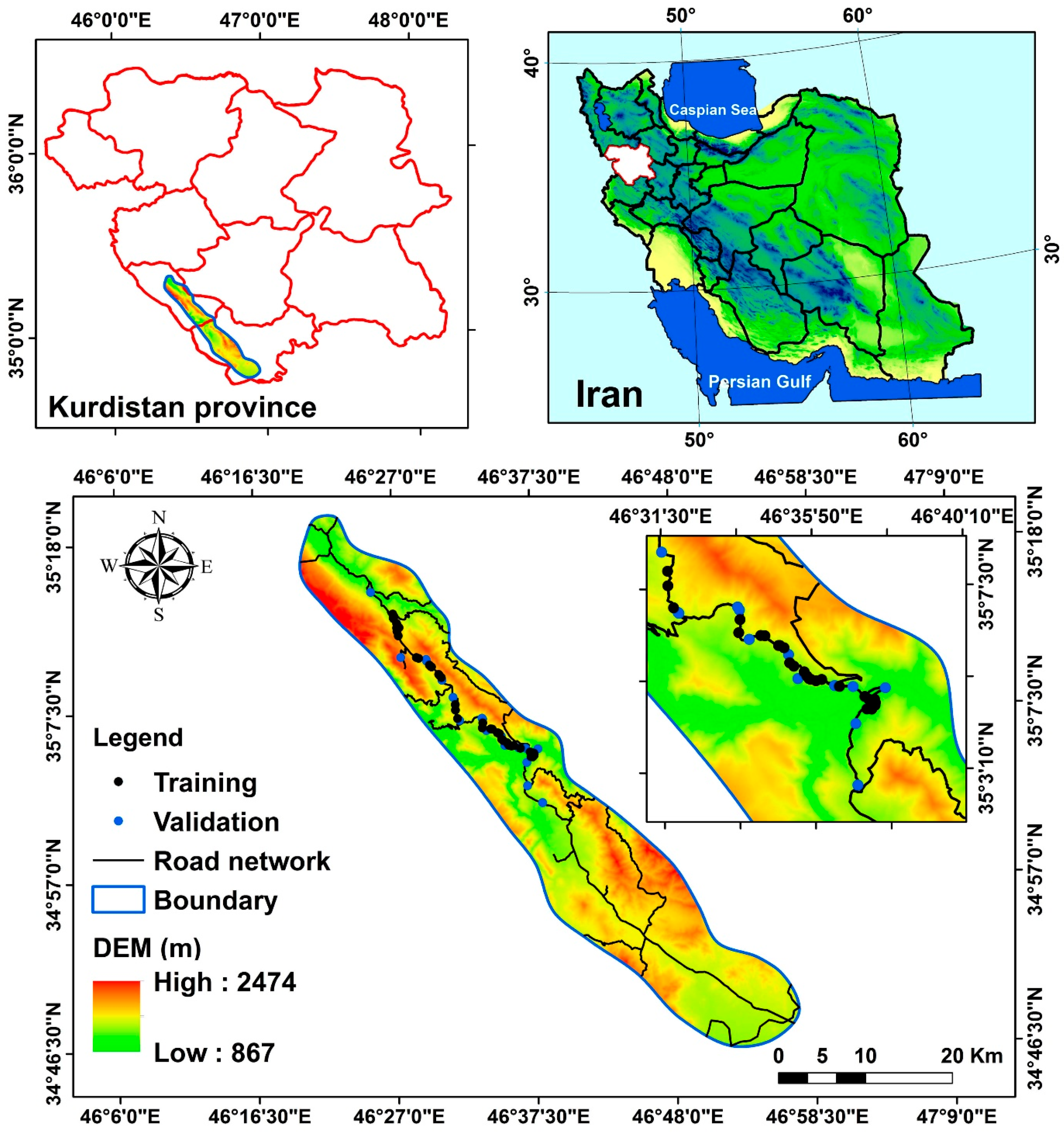
2. Study Area
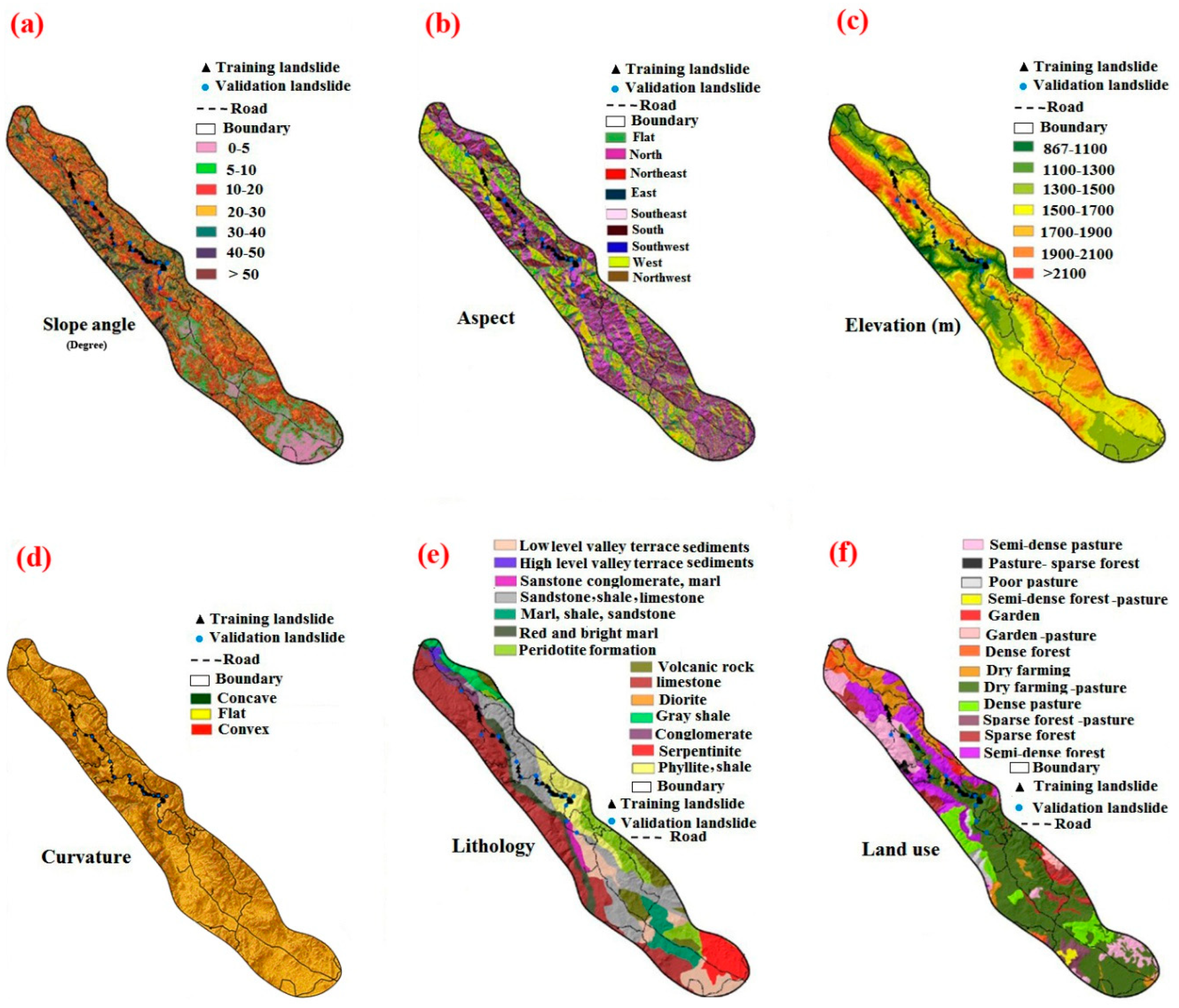
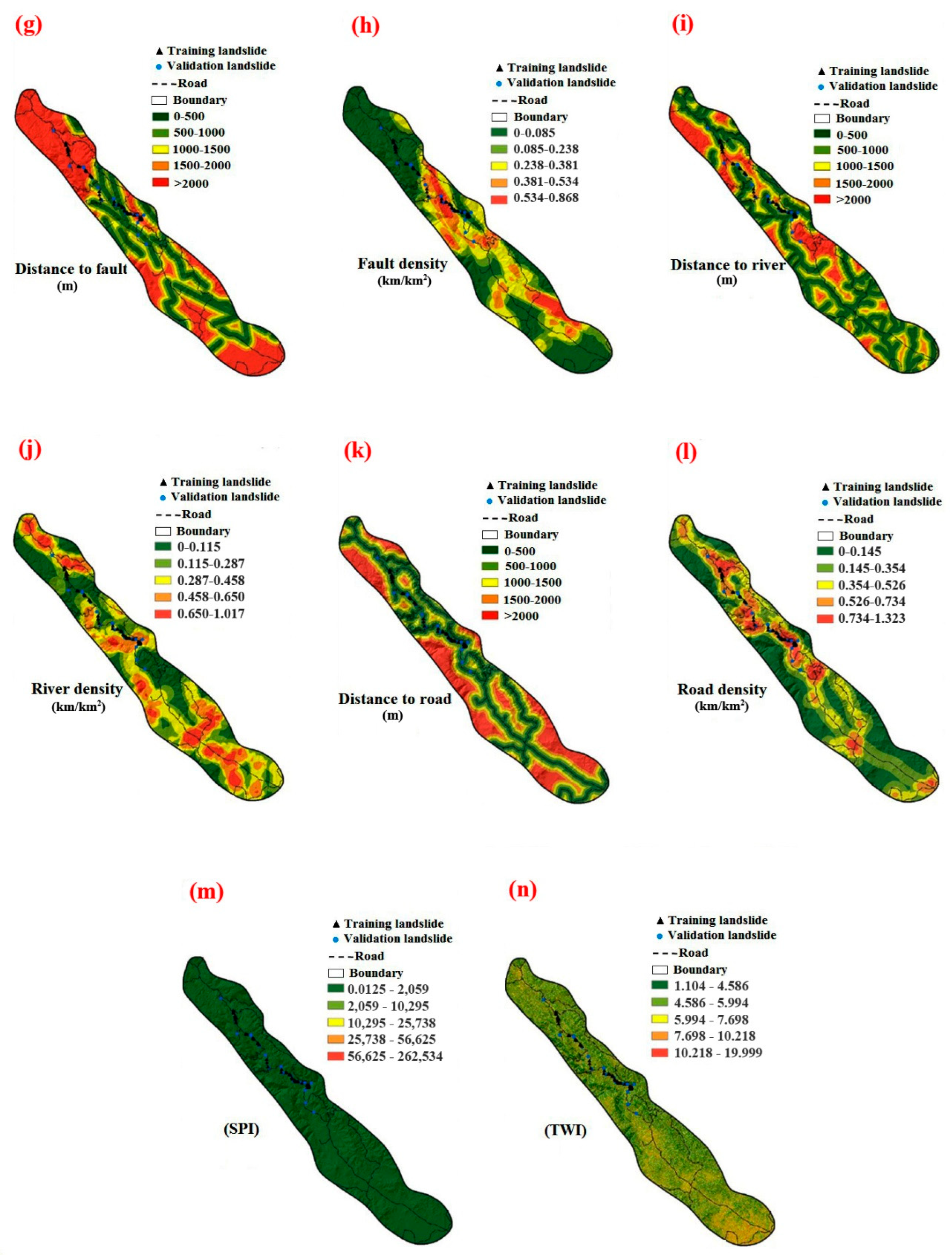
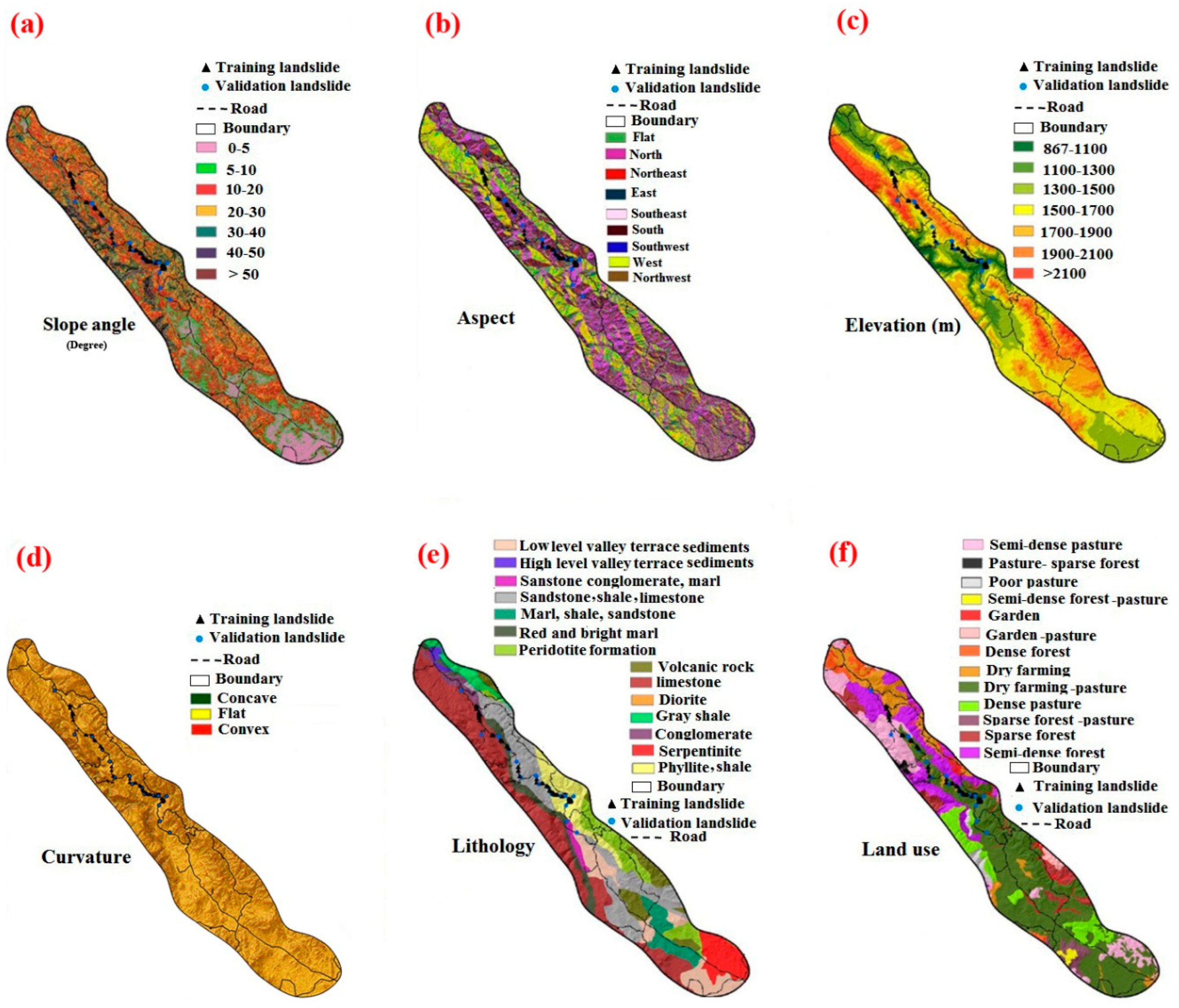
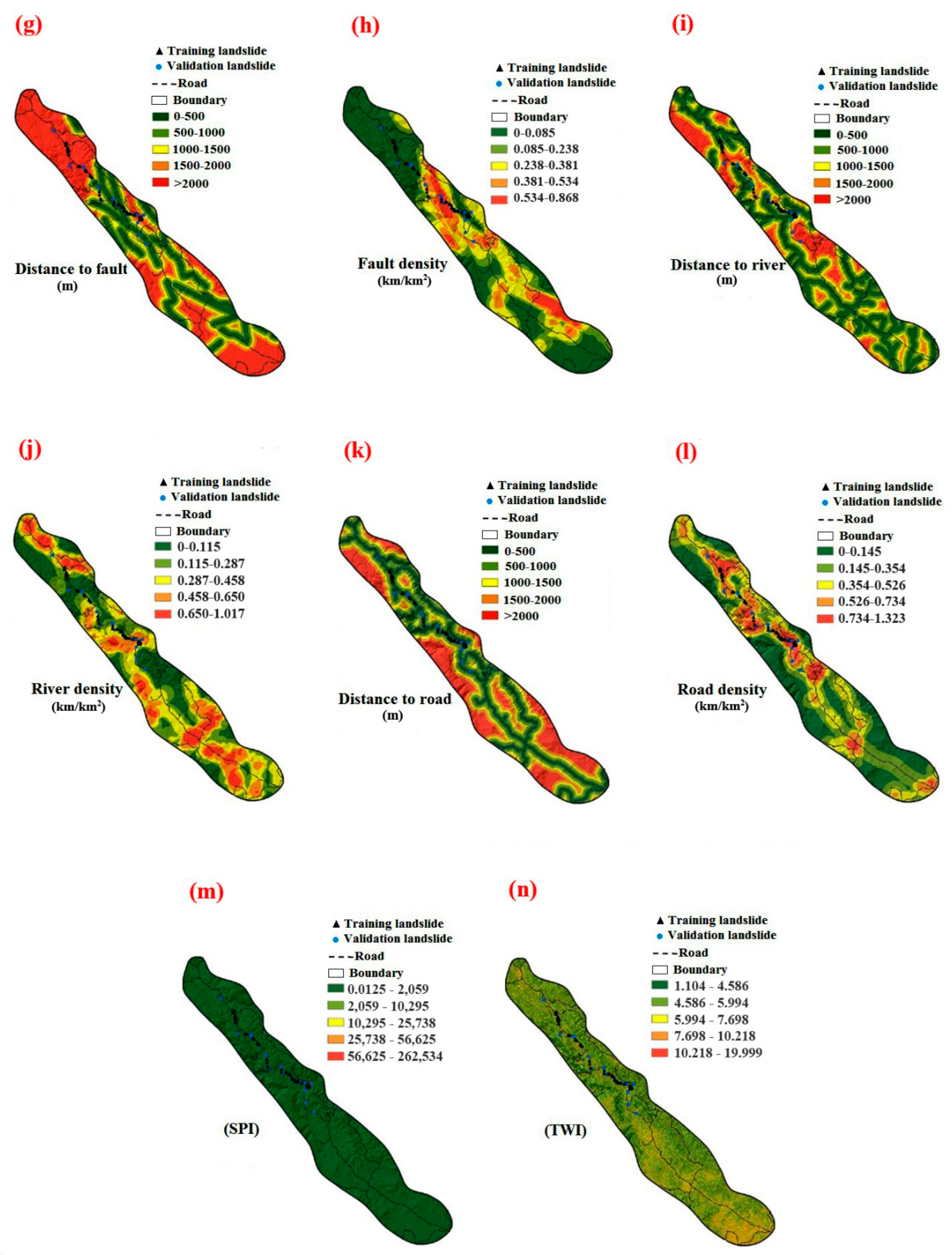
3. Landslide Conditioning Factors
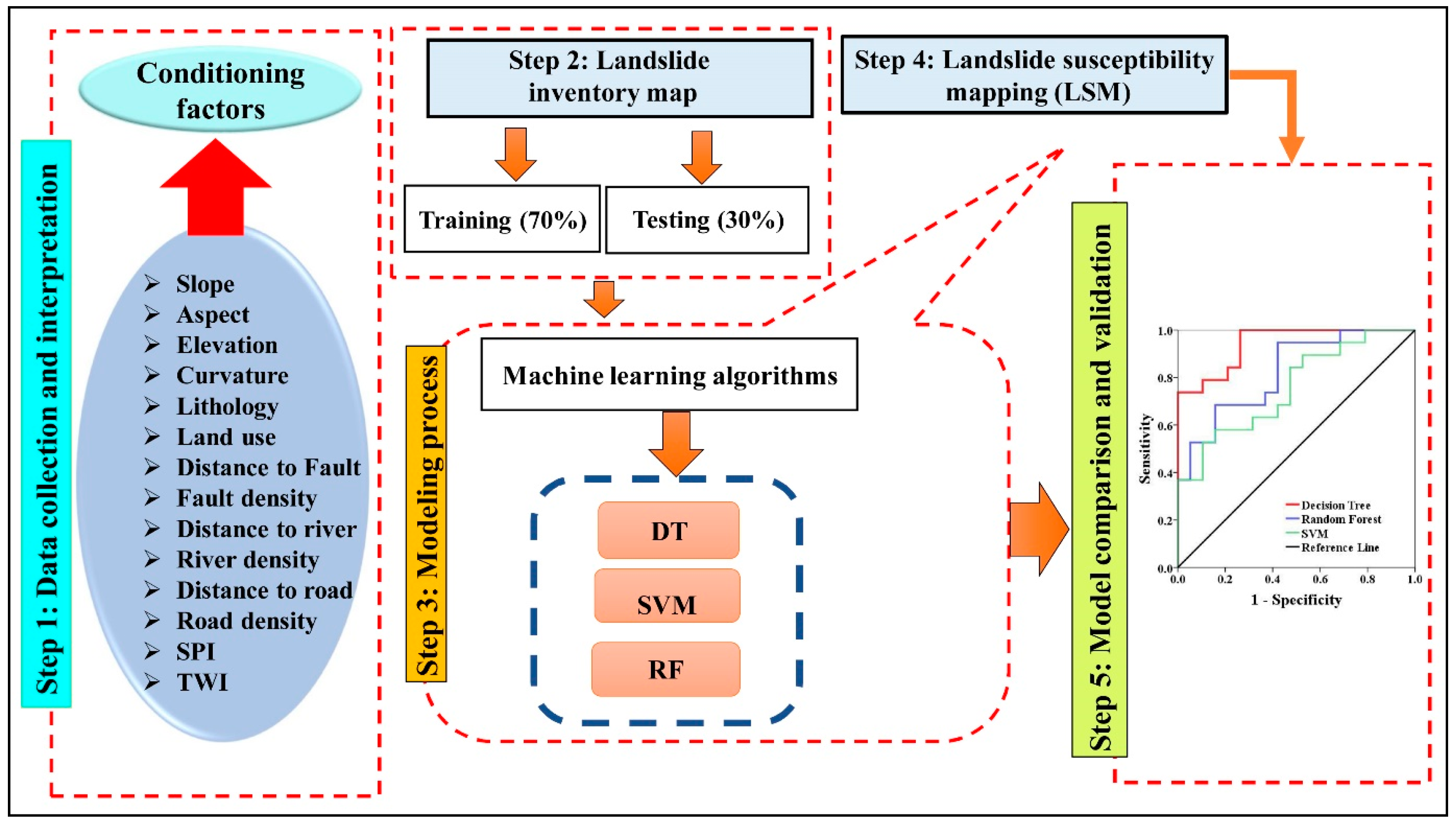
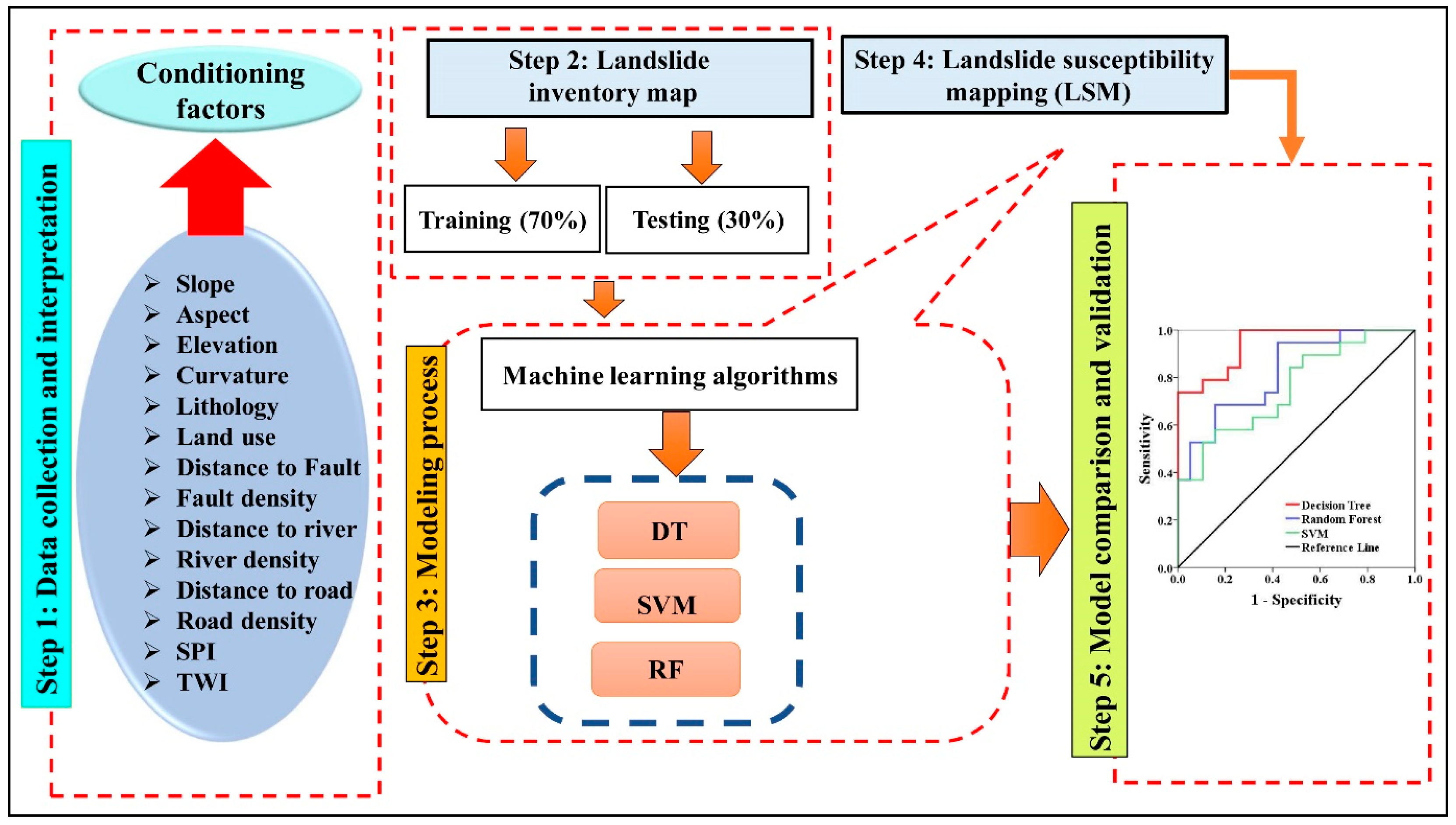
4. Methodology
4.1. Landslide Inventory Map (LIM)
4.2. Background of the MLAs
4.2.1. Random Forest
- (1)
- Determine each decision tree’s OOB error, denoted as errOOB1, using the matching out-of-bag (OOB) data in RF, with errOOB1 representing the average error for each calculation using only those predictions from the trees that are not contained in their respective bootstrap sample.
- (2)
- Add noise interference at random to every OOB sample, sampling feature X values. Additionally, a random adjustment may be made to the sample value at feature X. Recalculate the OOB data error after that, and then log the outcome as errOOB2.
- (3)
- Considering that RF contains NS trees, the following is the significance of feature X:
4.2.2. Support Vector Machines
4.2.3. Decision Tree Algorithm
4.2.4. Validation of the Models
4.2.5. Importance of the Factors Using Accuracy and the Gini Indexes
5. Results
5.1. Importance of the Factors on Landslide Occurrence
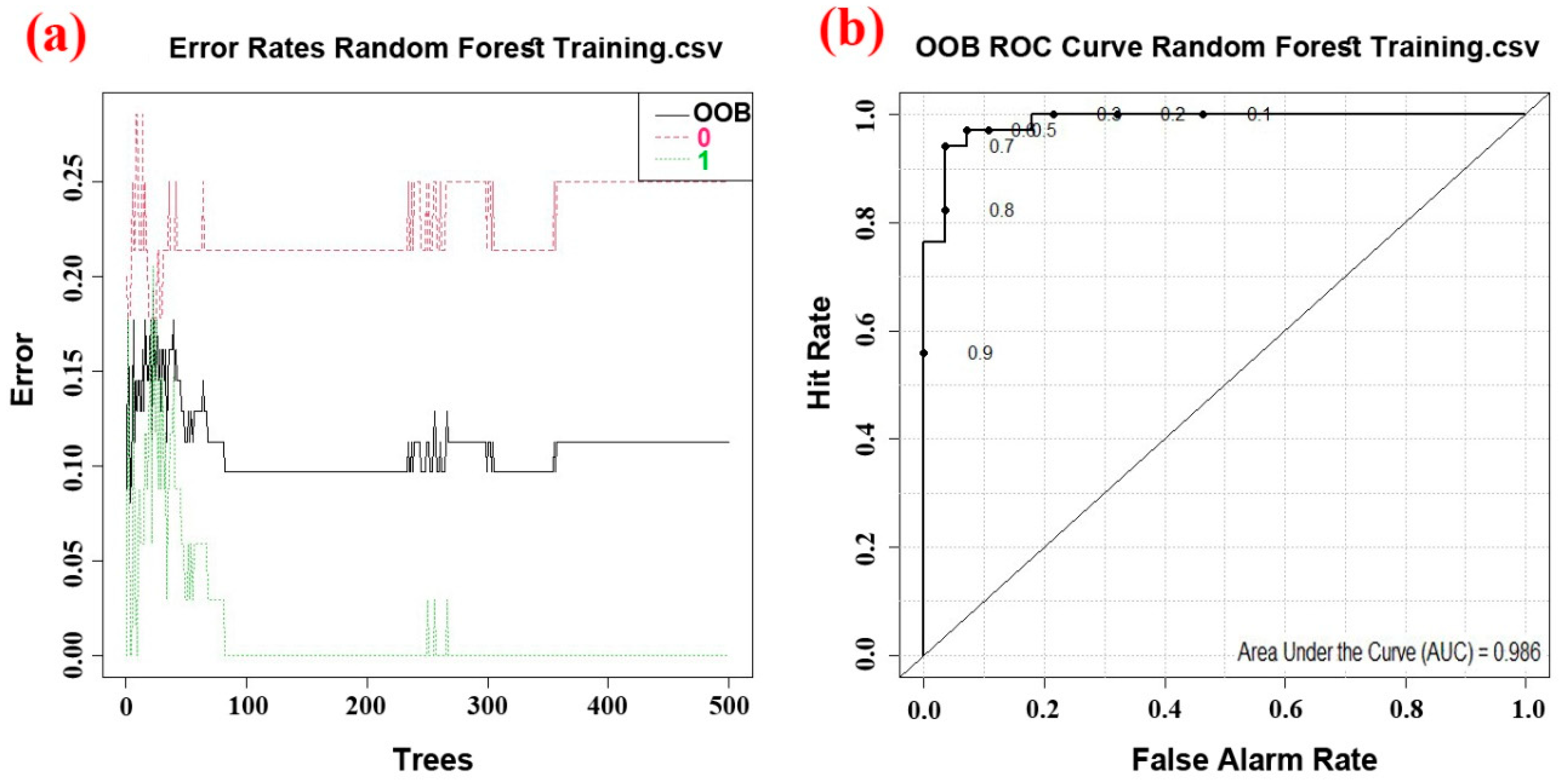
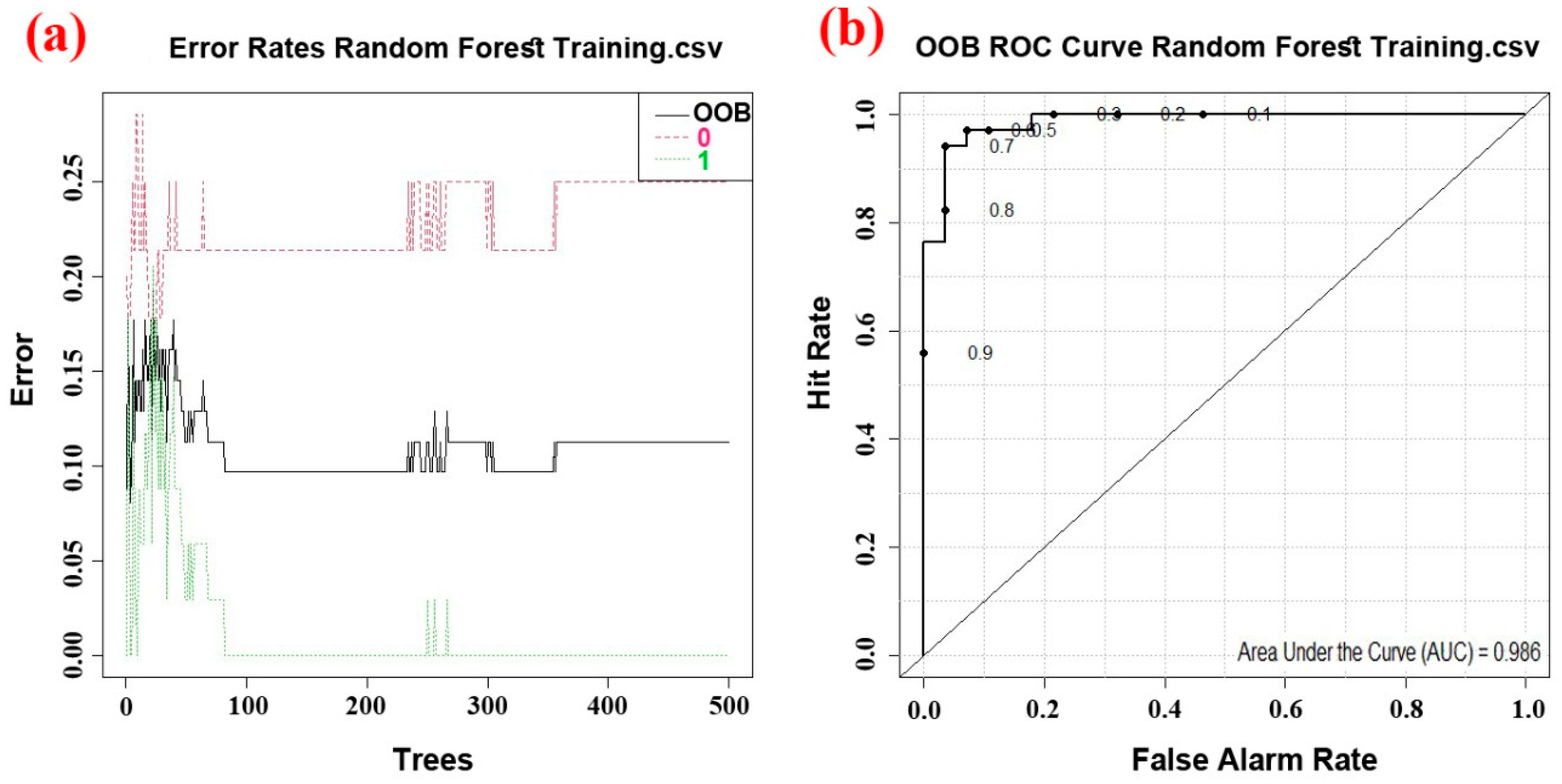
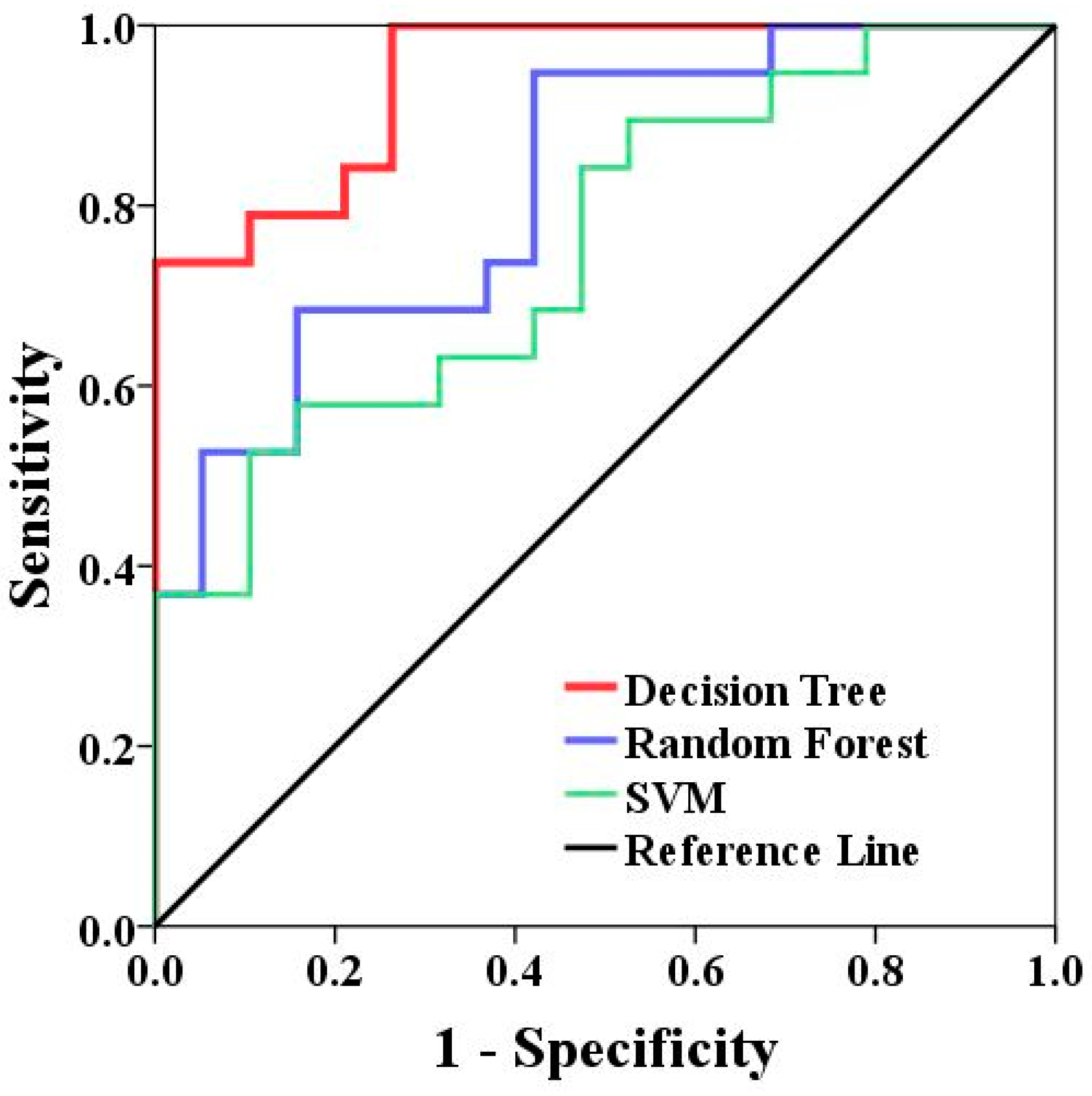
5.2. Performance of the Random Forest Model
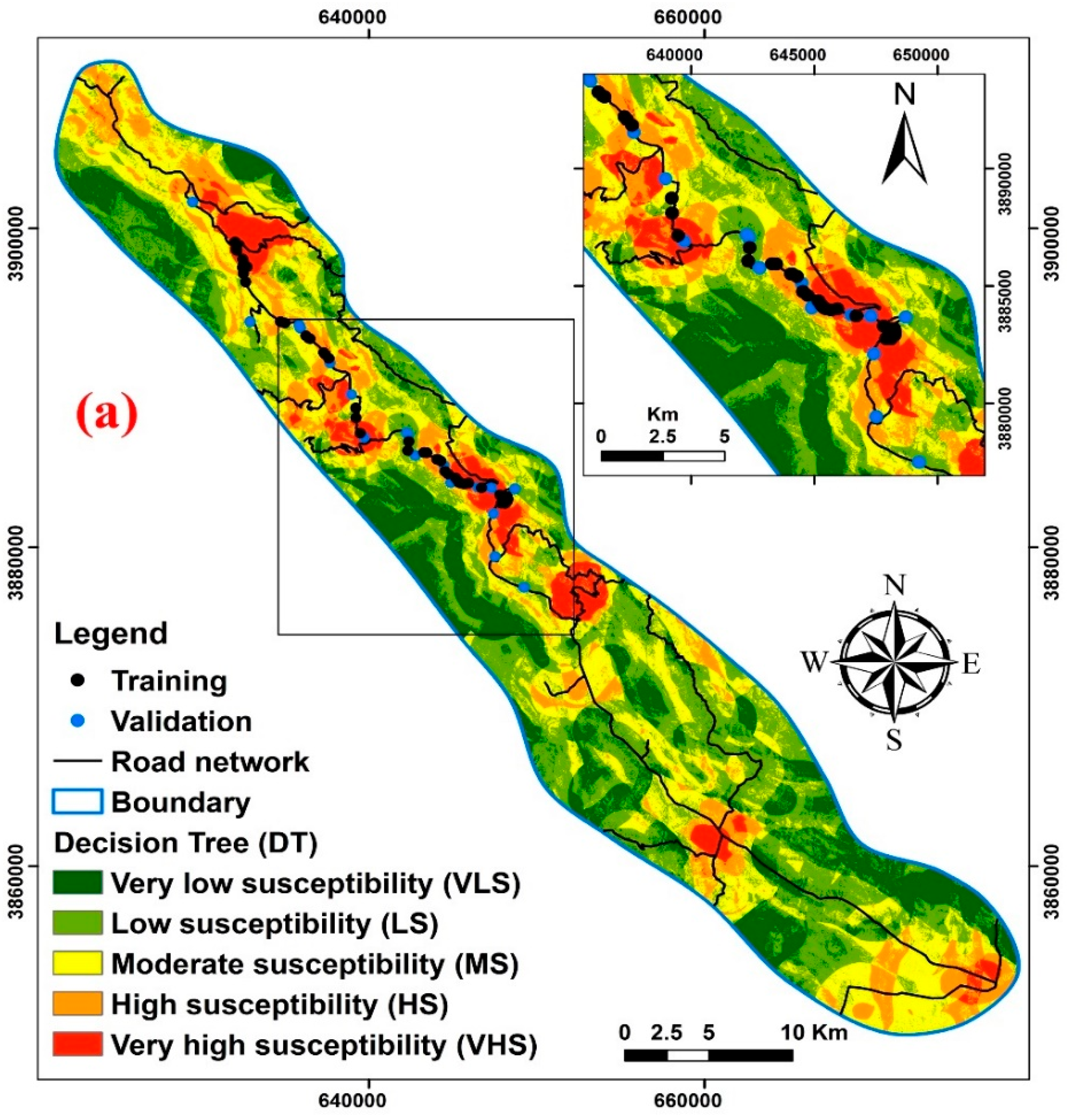
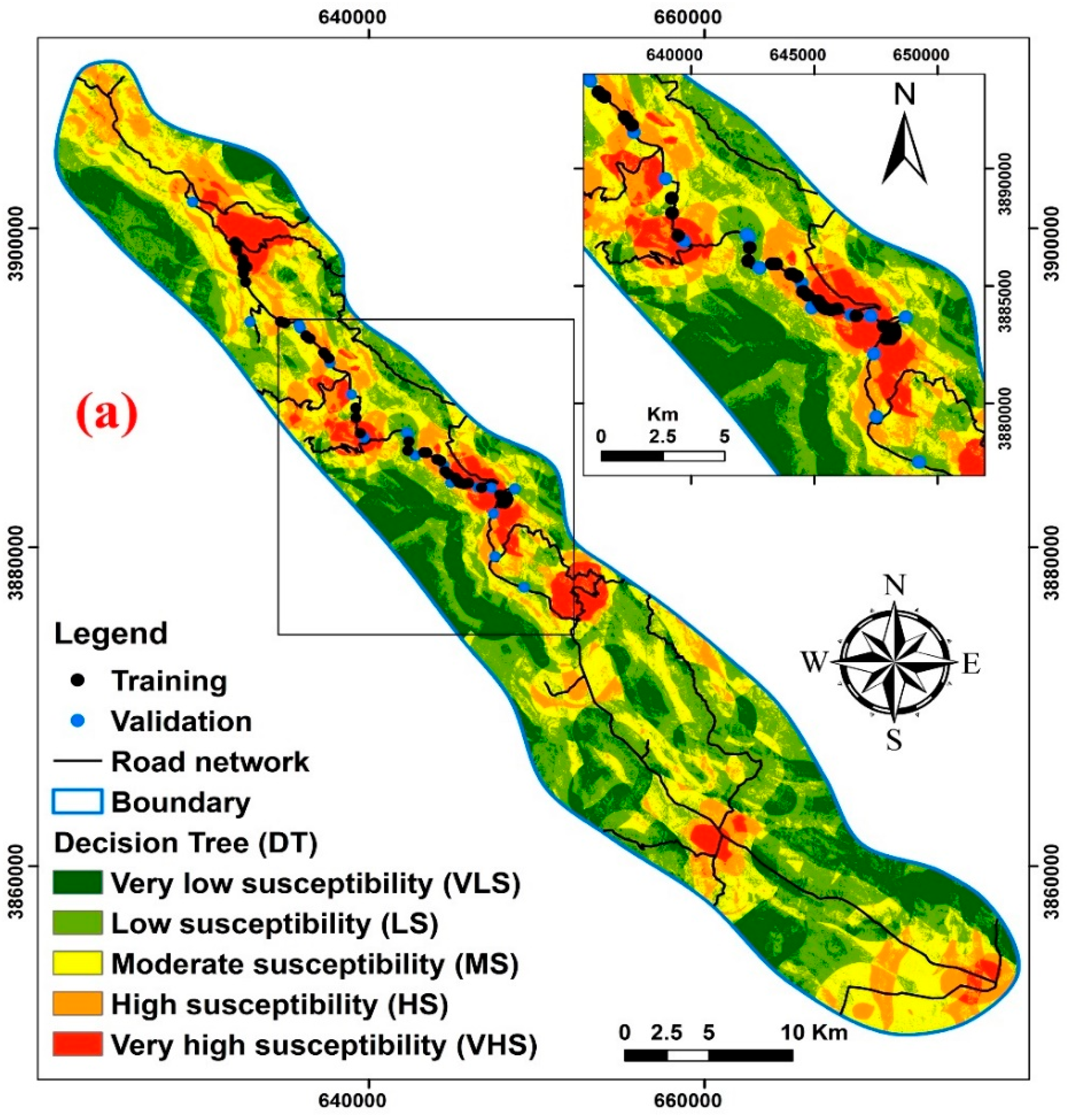
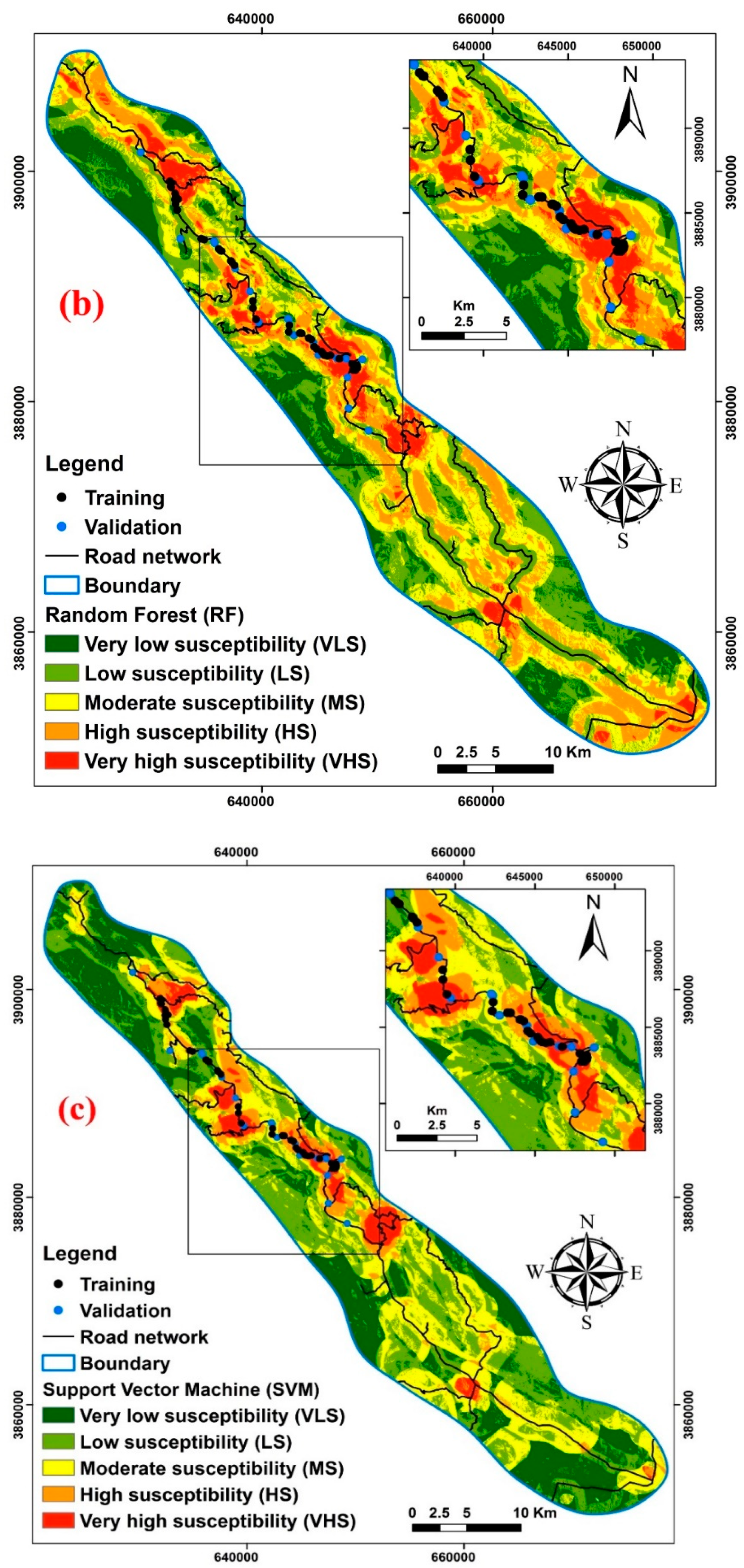
5.3. Developing Landslide Susceptibility Maps
6. Discussion
7. Conclusions
- (1)
- According to the results for two indices, Mean Decrease Accuracy and Mean Decrease Gini, the RF model was the most accurate in identifying the significance of landslide conditioning factors that caused landslide events in the current experiment. The most important factors in landslide susceptibility modelling for our research region include the distance to roads, road density, distance to rivers, geology, land use, elevation, distance to faults, aspect, fault density SPI, slope, TWI, and curvature.
- (2)
- LSMs were prepared using RF, DT, and SVM models adopting parameter tuning techniques. According on our research, the RF model performed and outperformed the DT and SVM models.
- (3)
- According to the landslide susceptibility maps, the most vulnerable locations are close to roads and follow the density of those roads. They are primarily in the middle of the research area as a result. The findings of this study can thus assist land developers, planners, and civil engineers with preliminary slope management and land-use planning, allowing them to take essential and scientific action to avert landslide dangers.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Assilzadeh, H.; Levy, J.K.; Wang, X. Landslide catastrophes and disaster risk reduction: A GIS framework for landslide prevention and management. Remote Sens. 2010, 2, 2259–2273. [Google Scholar] [CrossRef] [Green Version]
- Gordo, C.; Zêzere, J.L.; Marques, R. Landslide susceptibility assessment at the basin scale for rainfall-and earthquake-triggered shallow slides. Geosciences 2019, 9, 268. [Google Scholar] [CrossRef] [Green Version]
- Jones, S.; Kasthurba, A.; Bhagyanathan, A.; Binoy, B. Impact of anthropogenic activities on landslide occurrences in southwest India: An investigation using spatial models. J. Earth Syst. Sci. 2021, 130, 70. [Google Scholar] [CrossRef]
- Tehrani, F.S.; Calvello, M.; Liu, Z.; Zhang, L.; Lacasse, S. Machine learning and landslide studies: Recent advances and applications. Nat. Hazards 2022, 114, 1197–1245. [Google Scholar] [CrossRef]
- Saha, S.; Sarkar, R.; Roy, J.; Hembram, T.K.; Acharya, S.; Thapa, G.; Drukpa, D. Measuring landslide vulnerability status of Chukha, Bhutan using deep learning algorithms. Sci. Rep. 2021, 11, 16374. [Google Scholar] [CrossRef]
- Mavroulis, S.; Diakakis, M.; Kranis, H.; Vassilakis, E.; Kapetanidis, V.; Spingos, I.; Kaviris, G.; Skourtsos, E.; Voulgaris, N.; Lekkas, E. Inventory of Historical and Recent Earthquake-Triggered Landslides and Assessment of Related Susceptibility by GIS-Based Analytic Hierarchy Process: The Case of Cephalonia (Ionian Islands, Western Greece). Appl. Sci. 2022, 12, 2895. [Google Scholar] [CrossRef]
- Petrova, E. Natural hazard impacts on transport infrastructure in Russia. Nat. Hazards Earth Syst. Sci. 2020, 20, 1969–1983. [Google Scholar] [CrossRef]
- Khaliq, A.H.; Basharat, M.; Riaz, M.T.; Riaz, M.T.; Wani, S.; Al-Ansari, N.; Le, L.B.; Linh, N.T.T. Spatiotemporal landslide susceptibility mapping using machine learning models: A case study from district Hattian Bala, NW Himalaya, Pakistan. Ain Shams Eng. J. 2022, 101907. [Google Scholar]
- Aghdam, I.N.; Pradhan, B.; Panahi, M. Landslide susceptibility assessment using a novel hybrid model of statistical bivariate methods (FR and WOE) and adaptive neuro-fuzzy inference system (ANFIS) at southern Zagros Mountains in Iran. Environ. Earth Sci. 2017, 76, 237. [Google Scholar] [CrossRef]
- Ghasemian, B.; Shahabi, H.; Shirzadi, A.; Al-Ansari, N.; Jaafari, A.; Geertsema, M.; Melesse, A.M.; Singh, S.K.; Ahmad, A. Application of a Novel Hybrid Machine Learning Algorithm in Shallow Landslide Susceptibility Mapping in a Mountainous Area. Front. Environ. Sci. 2022, 10, 657. [Google Scholar] [CrossRef]
- Bai, S.-B.; Wang, J.; Lü, G.-N.; Zhou, P.-G.; Hou, S.-S.; Xu, S.-N. GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Akinci, H.; Yavuz Ozalp, A. Landslide susceptibility mapping and hazard assessment in Artvin (Turkey) using frequency ratio and modified information value model. Acta Geophys. 2021, 69, 725–745. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, Q.; Wang, F. Mapping the landslide susceptibility in Lantau Island, Hong Kong, by frequency ratio and logistic regression model. Ann. GIS 2015, 21, 191–208. [Google Scholar] [CrossRef]
- Erener, A.; Mutlu, A.; Düzgün, H.S. A comparative study for landslide susceptibility mapping using GIS-based multi-criteria decision analysis (MCDA), logistic regression (LR) and association rule mining (ARM). Eng. Geol. 2016, 203, 45–55. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Pathways and challenges of the application of artificial intelligence to geohazards modelling. Gondwana Res. 2021, 100, 290–301. [Google Scholar] [CrossRef]
- Wang, X.; Huang, F.; Fan, X.; Shahabi, H.; Shirzadi, A.; Bian, H.; Ma, X.; Lei, X.; Chen, W. Landslide susceptibility modeling based on remote sensing data and data mining techniques. Environ. Earth Sci. 2022, 81, 50. [Google Scholar] [CrossRef]
- Akinci, H.; Zeybek, M. Comparing classical statistic and machine learning models in landslide susceptibility mapping in Ardanuc (Artvin), Turkey. Nat. Hazards 2021, 108, 1515–1543. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Panahi, S.; Li, S.; Jaafari, A.; Ahmad, B.B. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. Catena 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides 2016, 13, 305–320. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Sevgen, E.; Kocaman, S.; Nefeslioglu, H.A.; Gokceoglu, C. A novel performance assessment approach using photogrammetric techniques for landslide susceptibility mapping with logistic regression, ANN and random forest. Sensors 2019, 19, 3940. [Google Scholar] [CrossRef] [Green Version]
- Akinci, H. Assessment of rainfall-induced landslide susceptibility in Artvin, Turkey using machine learning techniques. J. Afr. Earth Sci. 2022, 191, 104535. [Google Scholar] [CrossRef]
- Zhang, W.; Li, H.; Han, L.; Chen, L.; Wang, L. Slope stability prediction using ensemble learning techniques: A case study in Yunyang County, Chongqing, China. J. Rock Mech. Geotech. Eng. 2022, 14, 1089–1099. [Google Scholar] [CrossRef]
- Piacentini, D.; Devoto, S.; Mantovani, M.; Pasuto, A.; Prampolini, M.; Soldati, M. Landslide susceptibility modeling assisted by Persistent Scatterers Interferometry (PSI): An example from the northwestern coast of Malta. Nat. Hazards 2015, 78, 681–697. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Xu, Y.; Zhao, H.; Wang, J.; Zhong, Y.; Zhao, D.; Zang, Q.; Wang, S.; Zhang, F.; Shi, Y. The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection From Multisource Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9927–9942. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Gholamnia, K.; Ghamisi, P. The application of ResU-net and OBIA for landslide detection from multi-temporal sentinel-2 images. Big Earth Data 2022, 1–26. [Google Scholar] [CrossRef]
- He, Q.; Shahabi, H.; Shirzadi, A.; Li, S.; Chen, W.; Wang, N.; Chai, H.; Bian, H.; Ma, J.; Chen, Y. Landslide spatial modelling using novel bivariate statistical based Naïve Bayes, RBF Classifier, and RBF Network machine learning algorithms. Sci. Total Environ. 2019, 663, 1–15. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Lan, H.; Zhou, C.; Wang, L.; Zhang, H.; Li, R. Landslide hazard spatial analysis and prediction using GIS in the Xiaojiang watershed, Yunnan, China. Eng. Geol. 2004, 76, 109–128. [Google Scholar] [CrossRef]
- Kornejady, A.; Ownegh, M.; Bahremand, A. Landslide susceptibility assessment using maximum entropy model with two different data sampling methods. Catena 2017, 152, 144–162. [Google Scholar] [CrossRef]
- Yilmaz, I. Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: Conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ. Earth Sci. 2010, 61, 821–836. [Google Scholar] [CrossRef]
- Crosby, D.A. The Effect of DEM Resolution on the Computation of Hydrologically Significant Topographic Attributes. Master’s Thesis, University of South Florida, Tampa, FL, USA, 2006. [Google Scholar]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.-J.; Lee, S. Spatial prediction of urban landslide susceptibility based on topographic factors using boosted trees. Environ. Earth Sci. 2018, 77, 656. [Google Scholar] [CrossRef]
- Sezer, E.A.; Nefeslioglu, H.A.; Osna, T. An expert-based landslide susceptibility mapping (LSM) module developed for Netcad Architect Software. Comput. Geosci. 2017, 98, 26–37. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide susceptibility assessment in vietnam using support vector machines, decision tree, and Naive Bayes Models. Math. Probl. Eng. 2012, 2012, 974638. [Google Scholar] [CrossRef] [Green Version]
- Van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Pellicani, R.; Spilotro, G. Evaluating the quality of landslide inventory maps: Comparison between archive and surveyed inventories for the Daunia region (Apulia, Southern Italy). Bull. Eng. Geol. Environ. 2015, 74, 357–367. [Google Scholar] [CrossRef]
- De Oliveira, G.G.; Ruiz, L.F.C.; Guasselli, L.A.; Haetinger, C. Random forest and artificial neural networks in landslide susceptibility modeling: A case study of the Fão River Basin, Southern Brazil. Nat. Hazards 2019, 99, 1049–1073. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Hong, H.; Pradhan, B.; Bui, D.T.; Xu, C.; Youssef, A.M.; Chen, W. Comparison of four kernel functions used in support vector machines for landslide susceptibility mapping: A case study at Suichuan area (China). Geomat. Nat. Hazards Risk 2017, 8, 544–569. [Google Scholar] [CrossRef] [Green Version]
- Dixon, B.; Candade, N. Multispectral landuse classification using neural networks and support vector machines: One or the other, or both? Int. J. Remote Sens. 2008, 29, 1185–1206. [Google Scholar] [CrossRef]
- Fielding, A. Machine Learning Methods for Ecological Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Jones, M.J.; Fielding, A.; Sullivan, M. Analysing extinction risk in parrots using decision trees. Biodivers. Conserv. 2006, 15, 1993–2007. [Google Scholar] [CrossRef]
- Nefeslioglu, H.; Sezer, E.; Gokceoglu, C.; Bozkir, A.; Duman, T. Assessment of landslide susceptibility by decision trees in the metropolitan area of Istanbul, Turkey. Math. Probl. Eng. 2010, 2010, 901095. [Google Scholar] [CrossRef] [Green Version]
- Uwihirwe, J.; Hrachowitz, M.; Bogaard, T.A. Landslide precipitation thresholds in Rwanda. Landslides 2020, 17, 2469–2481. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Lee, D.-H.; Kim, Y.-T.; Lee, S.-R. Shallow landslide susceptibility models based on artificial neural networks considering the factor selection method and various non-linear activation functions. Remote Sens. 2020, 12, 1194. [Google Scholar] [CrossRef] [Green Version]
- Algehyne, E.A.; Jibril, M.L.; Algehainy, N.A.; Alamri, O.A.; Alzahrani, A.K. Fuzzy neural network expert system with an improved Gini index random forest-based feature importance measure algorithm for early diagnosis of breast cancer in Saudi Arabia. Big Data Cogn. Comput. 2022, 6, 13. [Google Scholar] [CrossRef]
- Park, S.; Hamm, S.-Y.; Kim, J. Performance evaluation of the GIS-based data-mining techniques decision tree, random forest, and rotation forest for landslide susceptibility modeling. Sustainability 2019, 11, 5659. [Google Scholar] [CrossRef] [Green Version]
- Geyer, C.J. Stat 5102 notes: More on confidence intervals. Univ. Minn. 2003, 24, 1–16. [Google Scholar]
- Tsakiris, G.; Pangalou, D.; Vangelis, H. Regional drought assessment based on the Reconnaissance Drought Index (RDI). Water Resour. Manag. 2007, 21, 821–833. [Google Scholar] [CrossRef]
- Postance, B.; Hillier, J.; Dijkstra, T.; Dixon, N. Extending natural hazard impacts: An assessment of landslide disruptions on a national road transportation network. Environ. Res. Lett. 2017, 12, 014010. [Google Scholar] [CrossRef]
- Jaafari, A.; Rezaeian, J.; Omrani, M.S.O. Spatial prediction of slope failures in support of forestry operations safety. Croat. J. For. Eng. J. Theory Appl. For. Eng. 2017, 38, 107–118. [Google Scholar]
- Schlögl, M.; Richter, G.; Avian, M.; Thaler, T.; Heiss, G.; Lenz, G.; Fuchs, S. On the nexus between landslide susceptibility and transport infrastructure–an agent-based approach. Nat. Hazards Earth Syst. Sci. 2019, 19, 201–219. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Nguyen-Thoi, T.; Qi, C.; Van Phong, T.; Dou, J.; Ho, L.S.; Van Le, H.; Prakash, I. Coupling RBF neural network with ensemble learning techniques for landslide susceptibility mapping. Catena 2020, 195, 104805. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Parameter | Source, Scale/Resolution |
|---|---|---|
| Topographic map | Elevation | ALOS PALSAR DEM 12.5 m |
| Slope | ||
| Aspect | ||
| Curvature | ||
| Geological map | Lithology | Geology map, 1:100,000 |
| Distance to fault | ||
| Faults density | ||
| Hydrological map | Topographic Wetness Index (TWI) | ALOS PALSAR DEM 12.5 m |
| Stream Power Index (SPI) | ||
| Distance to River (m) | ||
| River density | ||
| Land cover map | Land use | Iranian land use map |
| Distance to Road (m) | Topographical map, 1:50,000 and Google Earth imageries | |
| Road density |
| Factor | 0 | 1 | MDA | MDG |
|---|---|---|---|---|
| Distance to roads | 16.3 | 24.5 | 24.1 | 5.9 |
| Road density | 9.7 | 17.1 | 16.9 | 3.7 |
| Distance to river | 5.3 | 10.5 | 10.14 | 1.3 |
| Lithology | 7.6 | 8.3 | 9.4 | 1.7 |
| Land use | 2.2 | 9.5 | 8.7 | 1.78 |
| Elevation (m) | 1 | 8.8 | 8.3 | 0.83 |
| River density | 2.8 | 6.1 | 6.05 | 0.89 |
| Distance to fault | 1.8 | 5.8 | 5.9 | 0.52 |
| Aspect | 2.1 | 5.84 | 5.8 | 1.32 |
| Fault density | 2.08 | 4.01 | 3.9 | 0.38 |
| SPI | 0 | 0 | 0 | 0.21 |
| Slope | 0.36 | −0.21 | −0.1 | 0.31 |
| TWI | 0.92 | −1.12 | −0.26 | 0.43 |
| Curvature | −0.01 | −2.5 | −2.02 | 0.19 |
| Classes | SVM | DT | RF | |||
|---|---|---|---|---|---|---|
| Area (%) | Class Area (Hectares) | Area (%) | Class Area (Hectares) | Area (%) | Class Area (Hectares) | |
| VLS | 26.6 | 20,632.4 | 19.6 | 15,203.09 | 15.4 | 11,963.1 |
| LS | 32.6 | 25,306.9 | 33 | 25,621.56 | 28.9 | 22,422.6 |
| MS | 28.4 | 22,007 | 27.6 | 21,447.67 | 27.2 | 21,073.9 |
| HS | 7.4 | 5750.7 | 13.6 | 10,529.34 | 21.3 | 16,489.4 |
| VHS | 5 | 3875.5 | 6.2 | 4770.86 | 7.2 | 5623.5 |
| Models | Area | Std. Error a | Asymptotic Sig. b | Asymptotic 95% Confidence Interval | |
|---|---|---|---|---|---|
| Lower Bound | Upper Bound | ||||
| Decision Tree | 0.942 | 0.034 | 0.000 | 0.875 | 1.009 |
| Random Forest | 0.823 | 0.067 | 0.001 | 0.692 | 0.953 |
| SVM | 0.756 | 0.078 | 0.007 | 0.604 | 0.909 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahabi, H.; Ahmadi, R.; Alizadeh, M.; Hashim, M.; Al-Ansari, N.; Shirzadi, A.; Wolf, I.D.; Ariffin, E.H. Landslide Susceptibility Mapping in a Mountainous Area Using Machine Learning Algorithms. Remote Sens. 2023, 15, 3112. https://doi.org/10.3390/rs15123112
Shahabi H, Ahmadi R, Alizadeh M, Hashim M, Al-Ansari N, Shirzadi A, Wolf ID, Ariffin EH. Landslide Susceptibility Mapping in a Mountainous Area Using Machine Learning Algorithms. Remote Sensing. 2023; 15(12):3112. https://doi.org/10.3390/rs15123112
Chicago/Turabian StyleShahabi, Himan, Reza Ahmadi, Mohsen Alizadeh, Mazlan Hashim, Nadhir Al-Ansari, Ataollah Shirzadi, Isabelle D. Wolf, and Effi Helmy Ariffin. 2023. "Landslide Susceptibility Mapping in a Mountainous Area Using Machine Learning Algorithms" Remote Sensing 15, no. 12: 3112. https://doi.org/10.3390/rs15123112
APA StyleShahabi, H., Ahmadi, R., Alizadeh, M., Hashim, M., Al-Ansari, N., Shirzadi, A., Wolf, I. D., & Ariffin, E. H. (2023). Landslide Susceptibility Mapping in a Mountainous Area Using Machine Learning Algorithms. Remote Sensing, 15(12), 3112. https://doi.org/10.3390/rs15123112